Survey on LLM Training Today
References
Background:
- Token vector is embedded with positional information to preserve sequential nature of text
- input token vector is transformed into query (Q), key (K), and value (V) tensors via linear transformation and these are used to compute a weighted representation of the V tensor:
Attention(Q,K,V) = softmax(QK.t / sqrt(d))V
- Similarity between the queries and keys are used to calculate the weight
- allows for the LLM to focus on relevant parts of the input sequence
- Cost: Multi-Head Attention has high memory consumption (key-value cache)
- Addressed by Multi-Query Attention (MQA), Group-Query Attention (GQA), Multi-Latent Attention (MLA)
LLM Training Workloads
- GPT, LLaMa, MOSS → Transformer architecture (uniform architecture allows for optimization)
- Megatron, Alpa → accelerated training through hybrid parallelism
- DeepSpeed → reduces memory consumption through state-sharding optimizers
- Generally adopt self-supervised training on extensive datasets to create foundational models which are adapted for various tasks
Network Infrastructure for LLM
-
Chip-to-Chip Communication: data transfer between AI accelerators within a node
- Traditionally: PCI Express (PCIe) ⇒ tree topology with ~ 0 GB/s per lane
- limited to bandwidth, latency, and scalability
- Trend: NVLink → higher bandwidth and lower latency
- uses various topologies (cube-mesh, fully-connected, 3D-torus)
- employs shared memory models, specialized communication protocols, and synchronization mechanisms
- Traditionally: PCI Express (PCIe) ⇒ tree topology with ~ 0 GB/s per lane
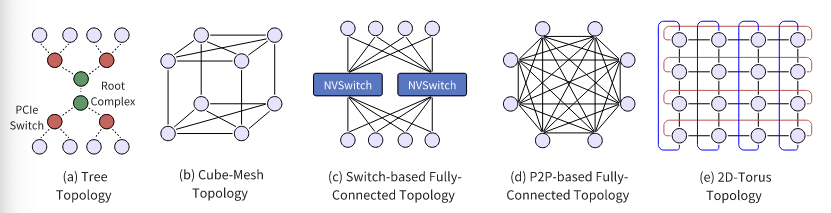

- Cube-Mesh Topology: NVLink-1.0 offers each link with BW of 160 GB/s
- planar-mesh for 4 GPUs
- cube-mesh topology for 8 GPUs
- Fully-Connected Topology: Switch-based / P2P-based
- Switch-based: NVSwitch1.0~3.0 (provides 300, 600, 900 GB/s respectively)
- P2P-based: bottleneck is the bandwidth of the directly connected link
- 2D/3D Torus: Used by Google’s TPU system
- 2D Torus: 1 chip connected to 4 of its neighbors
- 3D Torus: 4 connections per chip, but in a 3D dimensional cube
- Node-to-Node Communication: data transfer between nodes
- Remote Direct Memory Access (RDMA): allow direct memory access from memory of one node to another without involving OS
- InfiniBand: full stack technology for RDMA
- RDMA over Converged Ethernet (RoCE): allow RDMA over Ethernet
- RoCEv1: operates over Ethernet link layer protocol
- RoCEv2: operates over UDP
- Remote Direct Memory Access (RDMA): allow direct memory access from memory of one node to another without involving OS
- Network Topology: Composed of frontend and backend network
- Frontend Network: handling job management, model inference, storage activities
- Backend Network: dedicated to high-volume traffic generated during training
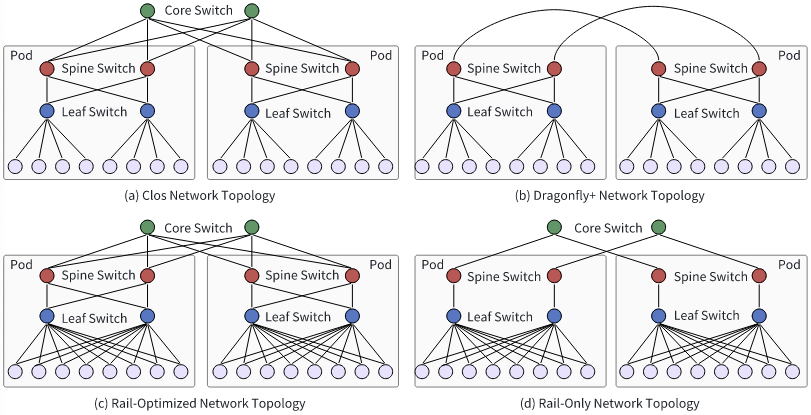
- Load Balancing & Congestion Control
- Load Balancing
- LLM Training → periodic bursts of network traffic due to gradient synchronization
- Equal-Cost Multi-Path routing (ECMP): uses hash algorithms to evenly distribute traffic across equivalent paths → hash-based scheme is inefficient for handling LLM training traffic (can result in congestion if elephant flows are routed to same link)
- Enhanced-ECMP (E-ECMP): 16 flows between two GPUs instead of 1
- hashing additional fields in the RoCE header of packets
- Others: HPN (identify precise disjoint equal paths and balance load within collective communicative library) / MegaScale (mitigate hash conflicts)
- Congestion Control
- Lossless transmission is important for RDMA
- Priority-based Flow Control (PFC): flow control mechanism that prevents packet loss
- when congested, device instructs upstream device to halt traffic in the queue to ensure zero packet loss
- can lead to HoL blocking
- Other options: DCQCN (Data Center Quantized Congestion Notification), TIMELY, High Precision Congestionl Control (HPCC), Edge Queued Datagram Service (EQDS), Robust Congestion Control (RoCC)
- MLTCP: interleave communication phase of jobs that compete for bandwidth based on key insight that training flows should adjust congestion window size based on the number of bytes sent in each training iteration
- CASSINI: optimizes job placement on network links by considering the communication patterns of different jobs
- MLT: leverages the fact that when training, the gradients of earlier layers are less important than those of later layers, and that the larger gradients are more significant that smaller ones → MLT prioritizes queuing or discarding packets based on the importance of gradients within them at the switch level to mitigate communication congestion issues
- Load Balancing
- Collective Communication
- Message Passing Interface (MPI) → programming model for large-scale scientific applications on parallel computing architectures
- Implementations: OpenMPI, MPICH2, MVAPICH, NCCL (NVIDIA), RCCL (AMD)
- Algorithms to Implement Coll. Comm:
- Ring Algorithm (e.g. Ring AllReduce)
- (Double Binary) Tree Algorithm : make two trees where one tree’s leaves are used as nodes for the second → split the data to broadcast/reduce (N/2) between the trees to maximize bandwidth utilization, because keeping a single tree would mean leaves do not participate as much in the communication compared to inner nodes
- Hybrid Algorithm
- 2D-Torus AllReduce:
- intra-node ring-based ReduceScatter
- inter-node tree-based AllReduce
- intra-node ring-based AllGather
- BlueConnect: multiple parallelizable ReduceScatter & AllGather for AllReduce
- 2D-Torus AllReduce:
- Message Passing Interface (MPI) → programming model for large-scale scientific applications on parallel computing architectures
- Communication Scheduling
- FIFO-based Scheduling: don’t wait for gradient computation to complete for all nodes in the backward pass → initiate communication as soon as gradient is ready
- Poseidon → FIFO queue to schedule AllReduce operators
- ensure that each layer starts it communication once its gradients are generated
- GradientFlow/Pytorch DDP → merge multiple AllReduce operators to one
- Poseidon → FIFO queue to schedule AllReduce operators
- Priority-based Scheduling:
- P3: overlap gradient communication of current layer with the forward computation of the next layer
- divides layers into fixed-sized slices and prioritizes synchronizing slices based on the order of processing in forward propagation
- P3: overlap gradient communication of current layer with the forward computation of the next layer
- FIFO-based Scheduling: don’t wait for gradient computation to complete for all nodes in the backward pass → initiate communication as soon as gradient is ready