Study on Batching
References
Problem
The general idea behind Orca is an interation-level batching algorithm that allows for different requests at various phases (prefill or decode) to be processed together in a batch. Traditionally, batching would occur only for requests that are in the same phase; shorter requests are padded and stalled until all other requests in the same batch complete, and incoming requests would wait until all previous batches are complete. This would cause inefficiency in GPU resource usage and also increase latency measurements (TTFT, ITL, E2E latency).
Suggestion from Paper
The paper therefore suggests to use iteration-level scheduling (selective batching) that allows higher flexibility in composing requests as a batch. Certainly, the prefill and decode stages have different computational characteristics, but these are all composed of tokens. Regardless of the tokens’ phases, these all go through non-Attention computations (linear/layer norm) operations. These can be done with a single tensor computation by flattening all the input tokens. Then, when an attention block is met, the tensor is split into requests, and are handled separately in different GPU cores. These are then merged together.
- What I was confused about:
- Prefill and Decode have different characeteristics. How can these be run in parallel?
- When the input requests in a batch are flattened, these are handled in a single go through matrix calculations
- When the inputs meet a Attention block, these are split in request-level and are handled in parallel
- Do batches finish together – since they must be merged in between?
- The batches finish together in each iteration but each iteration can have different requests being processed.
- Prefill and Decode have different characeteristics. How can these be run in parallel?
Evaluation Setup
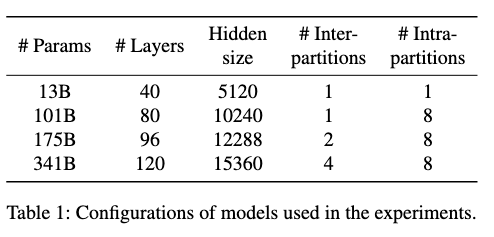
GPT-3 13B, 175B, 101B, 341B – maximum sequence length of 2048
- I had to look up the definition of maximum sequence length because 2048 seemed so small. This paper was in fact written in 2022. Maximum sequence length is the sum of input and output (generated) tokens.
- 13B can fit in a single A100 but others must be split (intra and inter layer parallelism)
Tests:
- Microbenchmark to assess performance of ORCA engine without iteration-level scheduling
- given batch of req, inject same batch into ORCA engine until all batches finish
- this mimics the behavior of canonical request-level scheduling
- E2E performance by emulating workload (synthetic input) because there was no LLM input dataset (sharegpt came out in 2023)
- the request rate per second is changed to test latency, and throughput
Things Learned about LLM Inference
- Maximum Sequence Length is capped out by the maximum number of positional encoding embeddings allowed in the model. Must retrain the entire model to increase maximum sequence length.
- Maximum Tokens is a user defined parameter to set the limit of the number of tokens used for the sum of input and output tokens.
- Orca pre-allocates maximum number of tokens
- Traditionally, inference would pre-allocate the maximum sequence length
- causes a lot of fragmentation – handled by vllm
SARATHI
Problem
Batch-level Scheduling used in FasterTransformer would obviously cause significant bubbles and wasted GPU cycles as shorter requests must wait for longer requests to finish within the batch, and incoming requests must also wait until the previous batch is complete. Iteration-level such as Orca provide a more fine-grained solution that allows a batch to include requests of different phases (with merge and split verbs) and different lengths (scheduling).
However, even Orca suffers from large pipeline bubbles because of the difference in prefill and decode stage characteristics. In other words, the distribution of request types (decode/prefill) in a batch can cause significant bubbles. Even the paper mentions that the overlapping of prefill and decode within a batch is a side-effect (thought it was funny and quite aggressive lol).
Suggestion from Paper
SARATHI proposes prefill chunking with decode piggybacking (decode-maximal batching). This method allows for a consistent batch composition of a prefill chunk followed by decode requests. This allows for us to consistently benefit from the increased arithmetic intensity (ratio of compute to memory load). Piggybacked decode batches improve arithmetic intensity by processing more tokens per weight load, because decode-only batches suffer from low arithmetic intensity as they are memory-bound.
We are also told that finding the correct balance of P:D is important for optimal piggybacking. I wonder if this is realistic because sequence lengths always vary in deployment scenarios. Determining the chunk size is also important and the paper uses 256 and 512. Decreasing it would allow prefills to be smaller and thus more prefill to use with other decode batches, but this would make the prefills too small, leading to inefficient matmuls.