Inference Simulation Notes
DistServe Motivation/Simulation Related Notes
Motivation
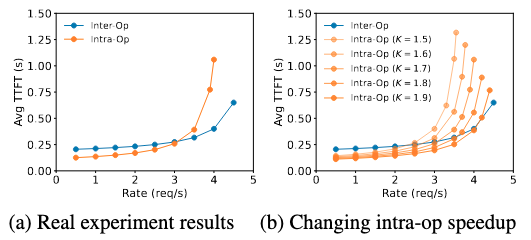
intra-op parallelism is better at low request rates, while inter-op parallelism is more effective at high request rates
- Total latency dominates queueing delay when request rates are low. Intra-op parallelism directly lowers the execution time of each request
- At higher request rates, queue waiting for requests grows and queuing delay becomes dominant. Inter-op parallelism creates a pipeline of model layers which allows system to handle more requests simultaneously
- Network engineers can test different parallelism models
- We are keeping the token length to 512, but we could test a distribution of token lengths for a distribution of request length
For intra-op parallelism, we introduce a speedup coefficient K, where 1 < K < 2, reflecting the imperfect speedup caused by high communication overheads of intra-op parallelism. With the execution time Ds = D K , the average TTFT for 2degree intra-op parallelism is:
\(Avg\_TTFT_{intra}=\frac{D}{K}+\frac{RD^2}{2K(K-RD)}\) The value of K depends on factors such as the input length, model architecture, communication bandwidth, and placement. As shown in Figure 4(b), a decrease in K notably reduces the efficacy of intra-op parallelism.
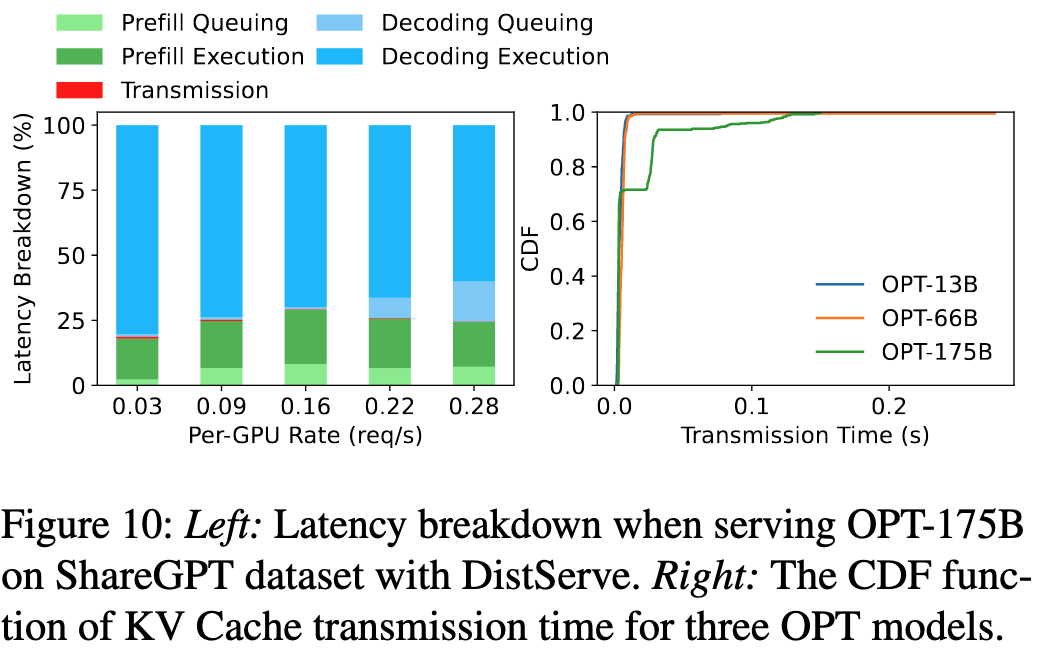
The paper also shows some diagrams that taking advantage of NVLINK’s bandwidth (600GB/s) utilization for KV Cache transfer can make this transfer negligible. Any need to focus on network communication in inference?
Simulation
- Profiles GPU-specific information
- depending on TP/PP, the maximum number of tokens one can process $L_m$
- time taken for prefill and decoding to calculate per-worker latency
- Input: # nodes, model type, pre-fill/decode stage target SLO, SLO target (90%), # of requests
- Output: Best parallelization configurations (TP, PP)
- Assuming prior knowledge of workload’s arrival process and input/output length distribution
- calculates SLO attainment
-
enumerate placements and finds maximum rate that meets SLO attainment target
Possible Directions:
- Multimodal LLM Training/Inference Simulation → background (DistTrain paper; SIGCOMM 25’)
- Paper proposes disaggregated Multimodal training where encoder, LLM, and generator have separate parallelism strategies to minimize bubbles and improve throughput
- they propose new batching algorithm to create equi-length input microbatches
- they mathematically show most optimal parallelism choice for each module
- DistTrain determines the optimal # of GPUs per module prior to training
- Modality Encoder → LLM Backbone → Modality Generator
- Each module in LLM have different computational demand
- E2E latency differs for different inputs used (image / video / text)
- Problems: Data heterogeneity, Model heterogeneity
- Paper proposes disaggregated Multimodal training where encoder, LLM, and generator have separate parallelism strategies to minimize bubbles and improve throughput
- Retrieval Augmented Generation for LLM simulation to allow deployment of different virtual servers or agents to simulate network patterns (multi-hop inference)
- Model Gateways?
- Agentic Traffic?